U ovom postu želim podijeliti svoje oduševljenje sa online platformom za podučavanje kvantitativne makroekonomiju te prikazati kako se pripadajući programski kodovi (modeli), pisani u Pythonu, mogu implementirati u programskom jeziku R. Riječ je o stranici Quantitative macroeconomics, čiji su autori T. Sargent i J. Stachurski. Stranica me nije oduševila zbog vrste kolegija na koji se odnosi (kvantitativna makroekonomija), već zbog upotrebe modernih alata u podučavanju tehnički zahtjevnog i kompleksnog područja. Iako platforma postoji već dosta vremena, čini mi se da veliki broj ljudi nije upoznat s njom. Zanimljivo je da ovu stranicu često preporučuju ne samo ekonomisti, nego i programeri, kao uvod u učenje Pythona za data science ili razne tehničke smjerove na poslijediplomskoj razini. U nastavku objašnjavam zašto me stranica oduševila.
Krenut ću od očiglednog. Sav sadržaj nalazi se na internetu i svima je dostupan. Sve što je potrebno za korištenje sadržaja je internet veza. S obzirom da je cjelokupni sadržaj prezentiran u html/markdown formatu, moguće je koristiti sve prednosti ovog pristupa, koji nisu dostupni u pisanoj formi. Primjerice, u tekst se kontinuirano dodaju poveznice koje čitatelja šalju na stranice sa detaljnim objašnjenima pojedinih fenomena. Nije potrebno objašnjavati pojmove koji su detaljno i precizno objašnjeni na nekim drugim stranicama.
Druga očigledna prednost je cijena. Sav sadržaj na stranici je besplatan. Cilj je edukacija, a ne zarada. Ako netko želi potaknuti cijeli QuantEcon projekt, može kupiti majice sa njihovim logom. Naglasak je dakle na dobrovoljnoj pomoći, a ne na plaćanju sadržaja. Ako je stranica kvalitetna i od pomoći, ljudi će biti spremni donirati određeni dio sredstava za njezino održavanje. Dodatno, programski jezici koji se koriste u analizi su open source (jednostavno rečeno besplatni). Ekonomska analiza se uobičajeno radi u Matlabu, čija licenca i nije baš jeftina. Iza Pythona stoji vrlo bogata zajednica koja može vrlo brzo pomoći svakome tko zapne u bilo kojoj fazi pisanja koda.
Treća, po meni najznačajnija prednost, je uključivanje kodova i rezultata u tekst. Kada sam kao student čitao o određenim ekonomskim modelima, najveće ograničenje mi je predstavljala njihova apstraktnost. Uvjeren sam da ljudi mnogo bolje shvaćaju takve modele kroz numeričko programiranje nego kroz suhoparni matematički model. Kada sami definirate parametre i napišete funkciju koja generira neki ekonomski fenomen, mnogo je lakše shvatiti predmet učenja, kako na razini intuicije, tako i na razini formalnih modela.
Valja napomenuti da su autori cijeli tekst, zajedno s kodovima i slikama prezentirali pomoću poznatog Python alata - Jupyter notebook. Isti se alat može koristiti i za druge programske jezike, ali se mogu koristiti i drugi alati (primjerice bookdown u R-u ). Ovo je najveća prednost knjige jer omogućuje ono što je u znanosti najbitnije - ponovljivost. Određeni model se može smatrati znanstvenim doprinosom jedino ako je ponovljiv. Iako je večina radova iz ekonomike tehnički reproducibilna, ponavljanje istraživanja u praksi je često vrlo nezgodno. Često autori u radovima ističu da su podaci ili kodovi korišteni u analizi dostupni na zahtjev. Ako uspijete doći do kodova, morate potrošiti vrijeme da shvatite strukturu koda i povežete sve s teorijom. Međutim QuantEcon daje teorijski pregled, poveznice na druge izvore, kodove i rezultate u jednom. Ako želite procijeniti osjetljivost rezultata na neki parametar potrebno je samo promijeniti jedan broj u tekstu.
Postoji još nekoliko sjajnih stvari oko QuantEcona. Predavanjima se kontinuirano dodaje novi sadržaj. Dok se nekada moralo godinama čekati na objavljivanje novog izdanja neke knjige, ovdje se novi sadržaj dodaje kontinuirano. Primjerice 24.01.2019 je dodan novi notebook u kojem se analizira “Krusell-Smith” model u programskom jeziku Julia. Nadalje, cijeli projekt je nadišao samo predavanje koje su pisali Sargent i Stachurski. Osim ovih predavanja postoje i ad hoc analize različitih ekonomista, te radionice i seminari. Više možete vidjeti ovdje.
Jedna stvar me zasmetala dok sam istraživao stranicu: nema R kodova :). Stoga sam “morao” replicirati nekoliko jednostavnih modela iz 3 poglavlja u R-u. Ovaj dio teksta je više tehnički, pa čitatelji koje ne zanima primjena u R-u mogu preskočiti ovaj dio.
Autori kroz cijeli tekst koriste klase za izgradnju modela. Više o klasama i objektno orijentiranom programiranju nalazi se u sljedećem potpoglavlju predavanja. Postavlja se pitanje, kako napraviti klasu u R-u, odnosno kako primijeniti OOP u R-u? Tri su moguća pristupa: S3 klase, S4 klase i R6 klase. Postoje još neke druge klase, ali one nisu zaživjele u R zajednici. Najpoznatija je S4 klasa (najviše se koristi u izrađivanju R paketa), ali činilo mi se da je R6 klasa prihvatljivija za navedeni problem, te vjernije može preslikati modele sa QuantEcon-a. Za konstruiranje R6 klase potrebna je samo jedna funkcija: R6::R6Class(). Unutar te funkcije postoje samo dva argumenta koja su nužna za funkcioniranje klase: classname i public.
Sada ću prikazati kako sam pomoću R-a. koristeći R6 klase, replicirao modele u QuantEconu. Za početak ću prikazati “Consumer” klasu koja se prikazuje nakon podnaslova “Example: A Consumer Class”. Potrebno je učitati R6 paket, definirati nazive klase i public argument:
CONSUER MODEL
library(R6)
library(tidyr)
library(assertive)
Consumer <- R6Class(
classname = "Consumer",
public = list(
wealth = NULL,
initialize = function(wealth) {
self$wealth <- wealth
},
earn = function(y) {
self$wealth = self$wealth + y
invisible(self)
},
spend = function(x) {
new_wealth = self$wealth - x
if (new_wealth < 0) {
message("Insufficent funds")
}else{
self$wealth = self$wealth - x
invisible(self)
}
}
)
)Zanimljivo je sto se događa u public argumentu, koji se sastoji od polja (ne-funkcije) wealth i tri metode: initialize , koja inicira vrijednost bogatstva pri kreiranju novog objekta, te earn i spend, koje su razumljive same po sebi. Iz ovako definirane klase se mogu jednostavno “stvoriti” različiti “potrošači” (primjeri):
# Here’s an example of usage
c1 <- Consumer$new(10) # Create instance with initial wealth 10
c1$spend(5)
c1$wealth## [1] 5c1$earn(15)
c1$spend(100)
# We can of course create multiple instances each with its own data
c1 <- Consumer$new(10)
c2 <- Consumer$new(12)
c2$spend(4)
c2$wealth## [1] 8c1$wealth## [1] 10c1 je potrošač jedan. Metoda new kreira novi instance na koji se potom primjenjuju metode earn i spend. Iako se ova klasa čini vrlo jednostavna, kompliciranije klase ustvari slijede isti princip! Primjerice, sljedeći model u tekstu je Solow-groth model (Python u predavanjima kod dolazi odmah nakon Consumer modela). Ovdje prikazujem R kod za Solow-growth model:
SOLOW GROWTH MODEL
library(ggplot2) # za vizualizaciju
Solow <- R6Class(
"Solow",
public = list(
n = NULL, # population growth rate
s = NULL, # savings rate
delta = NULL, # depreciation rate
alpha = NULL, # share of labor
z = NULL, # productivity
k = NULL, # current capital stock
initialize = function(n = 0.05, s = 0.25, delta = 0.1, alpha = 0.3, z = 2.0, k = 1.0) {
self$n <- n
self$s <- s
self$delta <- delta
self$alpha <- alpha
self$z <- z
self$k <- k
},
h = function(...) {
rhs <- (self$s * self$z * self$k**self$alpha + (1 - self$delta) * self$k) / (1 + self$n)
rhs
},
update = function(...) {
self$k <- self$h()
},
steady_state = function() {
ss <- ((self$s * self$z) / (self$n + self$delta))**(1 / (1 - self$alpha))
ss
},
generate_sequence = function(t) {
path = vector("numeric", t)
for (i in 1:t) {
path[i] <- self$k
self$update()
}
path
}
)
)
# plot
s1 <- Solow$new()
s2 <- Solow$new(k = 8.0)
t = 60
df <- data.frame(s1 = s1$generate_sequence(t), s2 = s2$generate_sequence(t),
ss = s1$steady_state(), y = 1:t, stringsAsFactors = FALSE)
df <- tidyr::gather(df, key = "variable", value = "value", - y)
ggplot(df[df$variable %in% c("s1", "s2"),], aes(x = y, y = value, color = variable)) +
geom_line() + geom_point() +
geom_line(data = df[df$variable == "ss",], aes(x = y, y = value), size = 1.2)
Kod izgleda mnogo kompliciranije, ali ustvari je primijenjen isti princip kao i kod potrošača! Razlika je samo u više varijabli i više metoda koje se primjenjuju na svaki instance. Za razumjeti modela, potrebno je razumijeti jednadžbu za h i steady state, ali to je stvar teorije i matematičkog izvoda. Čitatelj može sam mijenjati vrijednost parametara kako bi vidio njihov utjecaj na ponašanje krivulja na grafikonu. Čitatelj također može provjeriti da je output isti kao i Quantecon predavanjima. Varijabla ss je steady state, s1 je putanja kapitala uz početni stok kapitala 0, a s2 putanja kapitala u početni stok kapitala jednk 0.8.
Nakon što sam uspješno replicirao prva dva modela, bio sam dovoljno motiviran da repliciram market model i chaos model:
MARKET MODEL
Market <- R6Class(
"Market",
public = list(
ad = NULL,
bd = NULL,
az = NULL,
bz = NULL,
tax = NULL,
initialize = function(ad, bd, az, bz, tax) {
self$ad <- ad
self$bd <- bd
self$az <- az
self$bz <- bz
self$tax <- tax
assert_all_are_greater_than(ad, bz)
},
price = function() {
return((self$ad - self$az + self$bz * self$tax) / (self$bd + self$bz))
},
quantity = function() {
return(self$ad - self$bd * self$price())
},
consumer_surp = function() {
# == Compute area under inverse demand function == #
integrand <- function(x) {
(self$ad / self$bd) - (1 / self$bd) * x
}
area <- integrate(integrand, 0, self$quantity())
return(area$value - self$price() * self$quantity())
},
producer_surp = function() {
# == Compute area above inverse supply curve, excluding tax == #
integrand <- function(x) {
-(self$az / self$bz) + (1 / self$bz) * x
}
area <- integrate(integrand, 0, self$quantity())
return((self$price() - self$tax) * self$quantity() - area$value)
},
taxrev = function() {
return(self$tax * self$quantity())
},
inverse_demand = function(x) {
return(self$ad / self$bd - (1 / self$bd)* x)
},
inverse_supply = function(x) {
return(-(self$az / self$bz) + (1 / self$bz) * x + self$tax)
},
inverse_supply_no_tax = function(x) {
return(-(self$az / self$bz) + (1 / self$bz) * x)
}
)
)
# usage
m <- Market$new(15.0, 0.5, -2.0, 0.5, 3.0)
paste0("equilibrium price = ", m$price())## [1] "equilibrium price = 18.5"paste0("equilibrium quantity = ", m$quantity())## [1] "equilibrium quantity = 5.75"paste0("consumer surplus = ", m$consumer_surp())## [1] "consumer surplus = 33.0625"paste0("producer surplus = ", m$producer_surp())## [1] "producer surplus = 33.0625"m <- Market$new(15, .5, -2, .5, 3)
q_max <- m$quantity() * 2
q_grid <- seq(0, q_max, length.out = 100)
pd = m$inverse_demand(q_grid)
ps = m$inverse_supply(q_grid)
psno = m$inverse_supply_no_tax(q_grid)
df <- data.frame(y = 1:length(pd), pd = pd, ps = ps, psno = psno, stringsAsFactors = FALSE)
df <- tidyr::gather(df, key = "variable", value = "value", - y)
ggplot(df[df$variable %in% c("pd", "ps"),], aes(x = y, y = value, color = variable)) +
geom_line() +
geom_line(data = df[df$variable == "psno",], aes(x = y, y = value), linetype = "dashed") +
labs(x = "quantity", y = "price")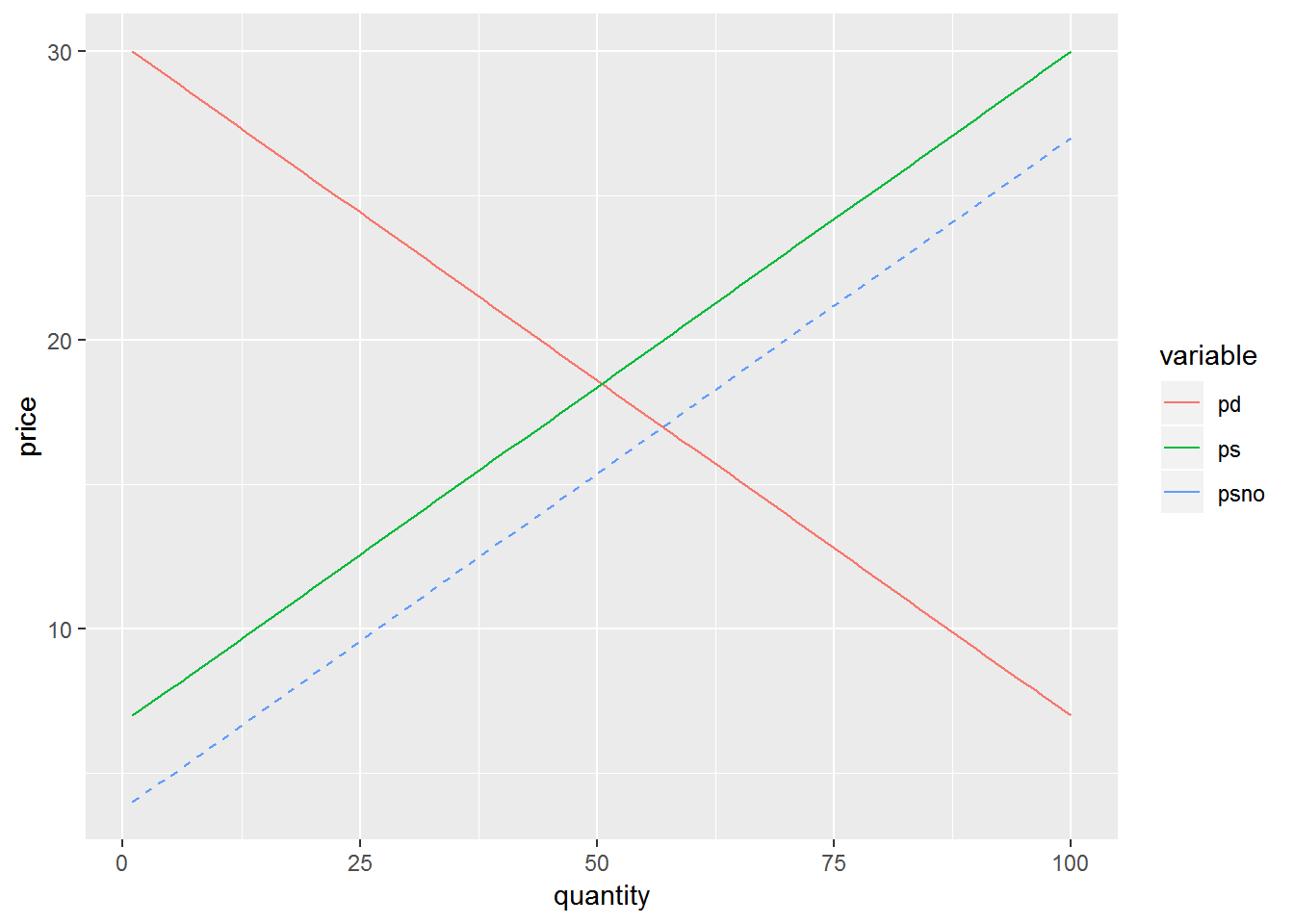
# computes dead weight loss from the imposition of the tax
deadw <- function(m) {
# == Create analogous market with no tax == #
m_no_tax <- Market$new(m$ad, m$bd, m$az, m$bz, 0)
# == Compare surplus, return difference == #
surp1 <- m_no_tax$consumer_surp() + m_no_tax$producer_surp()
surp2 <- m$consumer_surp() + m$producer_surp() + m$taxrev()
return(surp1 - surp2)
}
m <- Market$new(15, .5, -2, .5, 3)
deadw(m) # Show deadweight loss## [1] 1.125CHAOS
Chaos <- R6Class(
"Chaos",
public = list(
x = NULL,
r = NULL,
initialize = function(x0, r) {
self$x <- x0
self$r <- r
},
update = function() {
self$x <- self$r * self$x * (1 - self$x)
},
generate_sequence = function(n) {
path <- vector("numeric", n)
for (i in 1:n) {
path[i] <- self$x
self$update()
}
path
}
)
)
# Usage
ch = Chaos$new(0.1, 4.0)
ch$generate_sequence(5)## [1] 0.1000000 0.3600000 0.9216000 0.2890138 0.8219392ch <- Chaos$new(0.1, 4.0)
ts_length <- 250
df <- data.frame(y = 1:ts_length, x_t = ch$generate_sequence(ts_length), stringsAsFactors = FALSE)
ggplot(df, aes(x = y, y = x_t)) +
geom_line(color = "blue") + geom_point(color = "blue")
ch <- Chaos$new(0.1, 4.0)
r <- 2.5
result <- NULL
while (r < 4) {
ch$r <- r
t <- ch$generate_sequence(1000)[950:1000]
x <- cbind(r, t)
result <- rbind(result, x)
r <- r + 0.005
}
result <- as.data.frame(result, stringsAsFactors = FALSE)
ggplot(result, aes(x = r, y = t)) +
geom_point(color = "blue", size = 0.5)
Ponovno se može provjeriti da su grafikoni isti kao i u QuantEcon predavanjima. Kako bi bio siguran da se svi modeli mogu primjeniti u R-u probao sam replicirati i model Samuelsonovog akceleratora i sljedećeg potpoglavlja:
THE SAMUELSON ACCELERATORS
# graph
p1 <- seq(-2, 2, length.out = 100)
p2 <- -abs(p1) + 1
p3 <- rep(-1, length(p1))
p4 <- -(p1**2 / 4)
df <- cbind(p1, p2, p3, p4)
df <- as.data.frame(df, stringsAsFactors = FALSE)
# df <- tidyr::gather(df, key = "var", value = "value", - p1)
ggplot(data = df, aes(x = p1, y = p2)) +
geom_line() +
geom_line(aes(x = p1, y = p3)) +
geom_line(aes(x = p1, y = p4)) +
coord_cartesian(xlim = c(-3,3), ylim = c(-2,2)) +
geom_segment(aes(x = -3,y = 0, xend = 3, yend = 0), arrow = arrow(length = unit(0.3, "cm"), ends = "both")) +
geom_segment(aes(x = 0,y = -2, xend = 0, yend = 2), arrow = arrow(length = unit(0.3, "cm"), ends = "both")) +
annotate("text", 1.6, 1, label = "Expensive\ngrowth", size = 4.5) +
annotate("text", -1.5, 1, label = "Expensive\noscillations", size = 4.5) +
annotate("text", 0.05, -1.5, label = "Explosive oscillations", size = 4.5) +
annotate("text", 0.09, -0.5, label = "Damped oscillations", size = 4.5) +
annotate("text", -0.12, -1.12, label = "-1", size = 4) +
annotate("text", -0.12, 0.98, label = "1", size = 4) +
annotate("text", 3.05, -0.1, label = expression(rho[1]), size = 4) +
annotate("text", 0, 2.1, label = expression(rho[2]), size = 4) +
annotate("text", 0.8, 0.6, label = expression(rho[1]+rho[2]<1), size = 4, hjust = -0.1) +
geom_curve(aes(x = 0.8,y = 0.5, xend = 0.5, yend = 0.3), arrow = arrow(length = unit(0.2, "cm"), ends = "last")) +
annotate("text", 0.6, 0.8, label = expression(rho[1]+rho[2]==1), size = 4, hjust = -0.1) +
geom_curve(aes(x = 0.6,y = 0.8, xend = 0.38, yend = 0.6), arrow = arrow(length = unit(0.2, "cm"), ends = "last")) +
annotate("text", -1.3, 0.6, label = expression(rho[2]<1+rho[1]), size = 4, hjust = -0.1) +
geom_curve(aes(x = -0.8,y = 0.4, xend = -0.5, yend = 0.3), arrow = arrow(length = unit(0.2, "cm"), ends = "last"),
curvature = -0.5) +
annotate("text", -1, 0.8, label = expression(rho[2]==1+rho[1]), size = 4, hjust = -0.1) +
geom_curve(aes(x = -0.55,y = 0.6, xend = -0.4, yend = 0.6), arrow = arrow(length = unit(0.2, "cm"), ends = "last"),
curvature = -0.5) +
annotate("text", 1.8, -1.3, label = expression(rho[2]==-1), size = 4, hjust = -0.1) +
geom_curve(aes(x = 1.8,y = -1.3, xend = 1.5, yend = -1), arrow = arrow(length = unit(0.2, "cm"), ends = "last"),
curvature = -0.5) +
annotate("text", 1.5, -0.3, label = expression(rho[1]^2+4*rho[2]==0), size = 4, hjust = -0.1) +
geom_curve(aes(x = 1.5,y = -0.3, xend = 1.15, yend = -0.35), arrow = arrow(length = unit(0.2, "cm"), ends = "last"),
curvature = 0.5) +
annotate("text", 1.8, -0.6, label = expression(rho[1]^2+4*rho[2]<0), size = 4, hjust = -0.1) +
geom_curve(aes(x = 1.8,y = -0.6, xend = 1.4, yend = -0.7), arrow = arrow(length = unit(0.2, "cm"), ends = "last"),
curvature = 0.5) +
theme(axis.line = element_blank(), axis.text = element_blank(), axis.ticks = element_blank(),
axis.title = element_blank())
# Function to describe implications of characteristic polynomial
categorize_solution <- function(p1, p2) {
discriminant <- p1 ** 2 + 4 * p2
if (p2 > 1 + p1 | p2 < -1) {
print('Explosive oscillations')
} else if (p1 + p2 > 1) {
print('Explosive growth')
} else if (discriminant < 0) {
print('Roots are complex with modulus less than one; therefore damped oscillations')
} else {
print('Roots are real and absolute values are less than zero; therefore get smooth convergence to a steady state')
}
}
### Test the categorize_solution function
categorize_solution(1.3, -.4)## [1] "Roots are real and absolute values are less than zero; therefore get smooth convergence to a steady state"# Manual or “by hand” root calculations
y_nonstochastic <- function(y_0=100, y_1=80, alpha=.92, beta=.5, gama=10, n=80) {
roots <- vector("numeric")
p1 <- alpha + beta
p2 <- -beta
print(paste0('ρ_1 is ', p1))
print(paste0('ρ_2 is ', p2))
discriminant <- p1 ** 2 + 4 * p2
if (discriminant == 0) {
roots <- -p1 / 2
print('Single real root: ')
print(paste0(roots))
} else if (discriminant > 0) {
roots <- c((-p1 + sqrt(discriminant)) / 2, (-p1 - sqrt(discriminant)) / 2)
print('Two real roots: ')
print(paste0(roots))
} else {
roots <- c((-p1 + sqrt(as.complex(discriminant))) / 2, (-p1 - sqrt(as.complex(discriminant))) / 2)
print('Two complex roots: ')
print(paste0(roots))
}
if (all(abs(Re(roots)) < 1)) {
print('Absolute values of roots are less than one')
} else {
print('Absolute values of roots are not less than one')
}
transition <- function(x, t) {
return(p1 * x[t - 1] + p2 * x[t - 2] + gama)
}
y_t = c(y_0, y_1)
for (t in 3:n) {
y_t[t] <- transition(y_t, t)
}
return(y_t)
}
y_t <- y_nonstochastic()## [1] "<U+03C1>_1 is 1.42"
## [1] "<U+03C1>_2 is -0.5"
## [1] "Two real roots: "
## [1] "-0.645968757625672" "-0.774031242374328"
## [1] "Absolute values of roots are less than one"y_t <- data.frame(t = 1:length(y_t),y_t = y_t, stringsAsFactors = FALSE)
ggplot(data = y_t, aes(x = t, y = y_t)) +
geom_line(color = "blue") +
labs(x = "Time t", y = expression(Y[t]))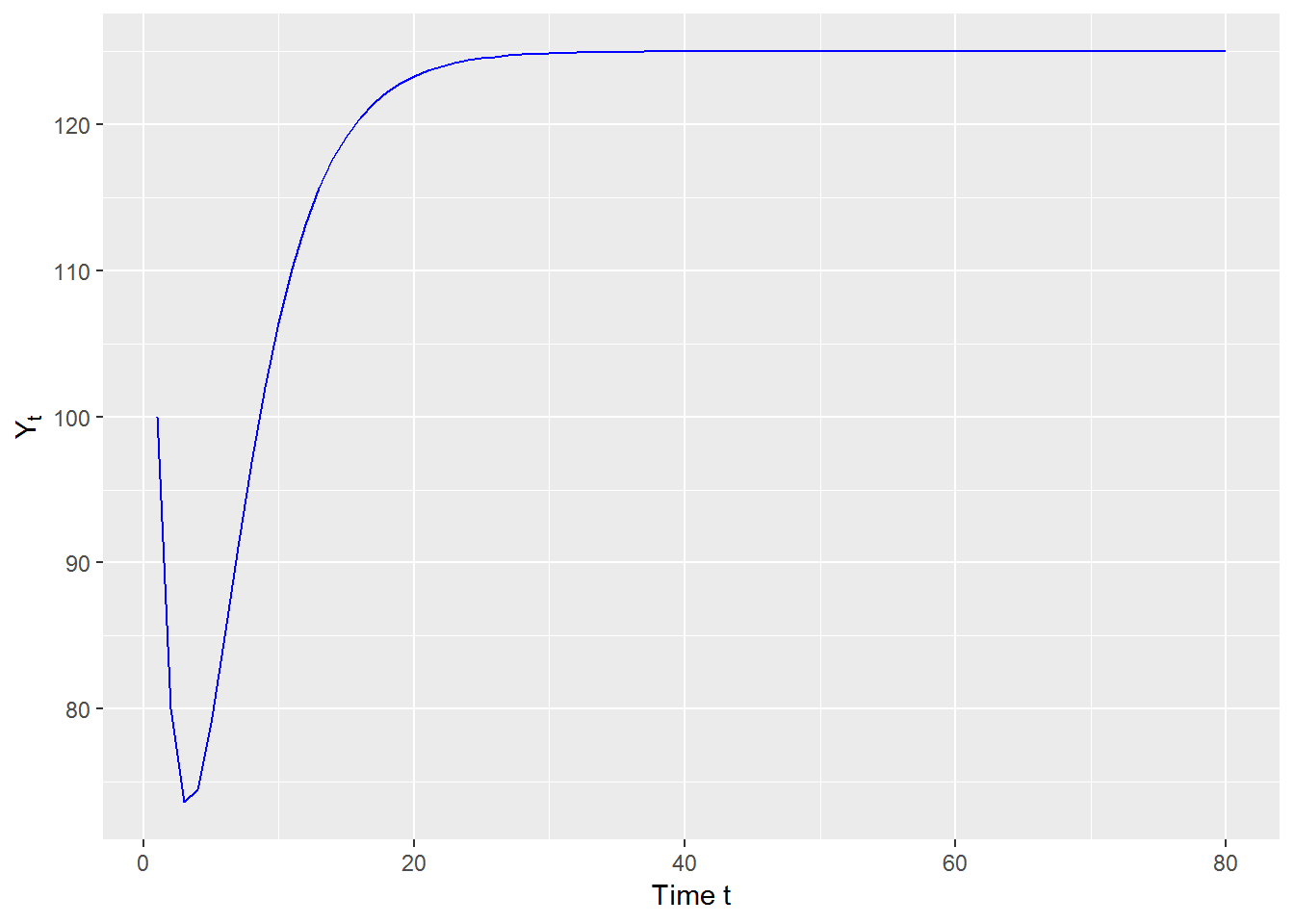
# Reverse engineering parameters to generate damped cycles
f <- function(r, phi) {
g1 <- complex(modulus = r, argument = phi) # Generate two complex roots
g2 <- complex(modulus = r, argument = -phi)
p1 <- g1 + g2 # Implied ρ1, ρ2
p2 <- -g1 * g2
b <- -p2 # Reverse engineer a and b that validate these
a <- p1 - b
list(p1, p2, a, b)
}
## Now let's use the function in an example
## Here are the example paramters
r = .95
period = 10 # Length of cycle in units of time
phi = 2 * pi/period
## Apply the function
f1 <- f(r, phi)
paste0("a, b = ", f1[[3]], ", ", f1[[4]])## [1] "a, b = 0.6346322893124+0i, 0.9025+0i"paste0("p1, p2 = ", f1[[1]], ", ", f1[[2]])## [1] "p1, p2 = 1.5371322893124+0i, -0.9025+0i"## Print the real components of ρ1 and ρ2
p1 = Re(f1[[1]])
p2 = Re(f1[[2]])
p1; p2## [1] 1.537132## [1] -0.9025# Reverse engineered complex roots: example
r = 1 # generates undamped, nonexplosive cycles
period = 10 # length of cycle in units of time
phi = 2 * pi/period
## Apply the reverse engineering function f
f1 <- f(r, phi)
a = Re(f1[[3]]) # drop the imaginary part so that it is a valid input into y_nonstochastic
b = Re(f1[[4]])
a; b## [1] 0.618034## [1] 1ytemp <- y_nonstochastic(alpha = a, beta = b, y_0 = 20, y_1 = 30)## [1] "<U+03C1>_1 is 1.61803398874989"
## [1] "<U+03C1>_2 is -1"
## [1] "Two complex roots: "
## [1] "-0.809016994374947+0.587785252292473i"
## [2] "-0.809016994374947-0.587785252292473i"
## [1] "Absolute values of roots are less than one"y_t <- data.frame(t = 1:length(ytemp),y_t = ytemp, stringsAsFactors = FALSE)
ggplot(data = y_t, aes(x = t, y = y_t)) +
geom_line(color = "blue") +
labs(x = "Time t", y = expression(Y[t]))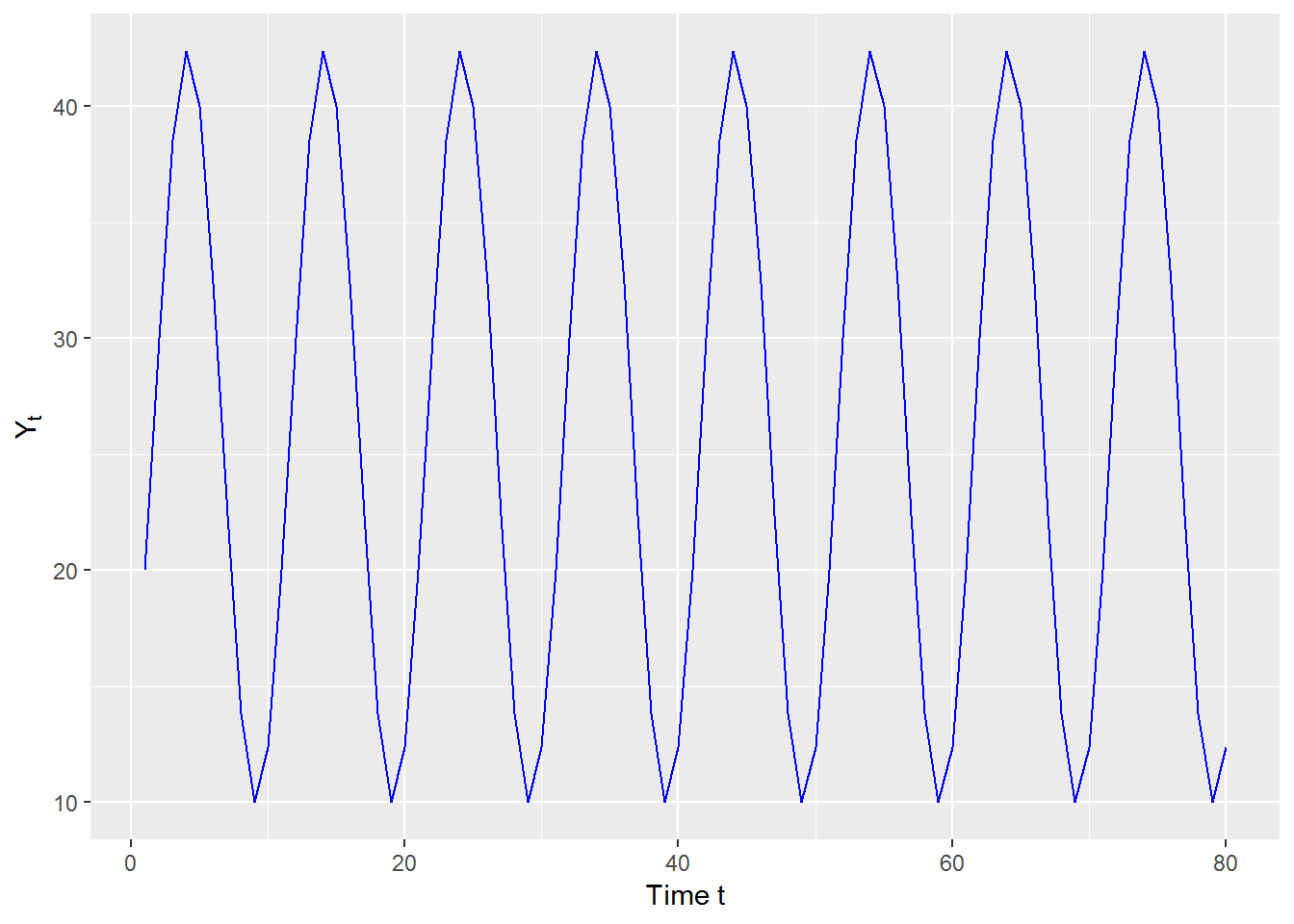
# Stochastic shocks
y_stochastic <- function(y_0=0, y_1=0, alpha=0.8, beta=0.2, delta=10, n=100, sigma=5) {
# Useful constants
p1 = alpha + beta
p2 = -beta
# Categorize solution
categorize_solution(p1, p2)
# Find roots of polynomial
roots <- polyroot(c(-p2, -p1, 1))
# Check if real or complex
if (all(is.complex(roots))) {
print(roots)
print('Roots are complex')
roots <- Re(roots)
} else {
print(roots)
print('Roots are real')
}
# Check if roots are less than one
if (all(abs(roots) < 1)) {
print('Roots are less than one')
} else {
print('Roots are not less than one')
}
# Generate shocks
epsilon = rnorm(n, 0, 1)
# Define transition equation
transition <- function(x, t) {
return(p1 * x[t - 1] + p2 * x[t - 2] + delta + sigma * epsilon[t])
}
# Set initial conditions
y_t <- c(y_0, y_1)
# Generate y_t series
for (t in 1:n) {
y_t <- c(y_t, transition(y_t, t))
}
return(y_t)
}
x <- y_stochastic()## [1] "Roots are real and absolute values are less than zero; therefore get smooth convergence to a steady state"
## [1] 0.2763932+0i 0.7236068-0i
## [1] "Roots are complex"
## [1] "Roots are less than one"df <- data.frame(t = 1:length(x), y_t = x, stringsAsFactors = FALSE)
ggplot(df, aes(x = t, y = y_t)) +
geom_line(color = "blue")
# simulation in which there are shocks and the characteristic polynomial has complex roots
r <- 0.97
period <- 10 # length of cycle in units of time
phi = 2 * pi/period
### apply the reverse engineering function f
f1 <- unlist(f(r, phi))
p1 <- f1[1]; p2 <- f1[2]; a <- f1[3]; b <- f1[4]
a <- Re(a) # drop the imaginary part so that it is a valid input into y_nonstochastic
b <- Re(b)
paste0("a, b = ", a, " ", b)## [1] "a, b = 0.628592969087398 0.9409"x <- y_stochastic(y_0 = 40, y_1 = 42, alpha = a, beta = b, sigma = 2, n = 100)## [1] "Roots are complex with modulus less than one; therefore damped oscillations"
## [1] 0.7847465+0.5701517i 0.7847465-0.5701517i
## [1] "Roots are complex"
## [1] "Roots are less than one"df <- data.frame(t = 1:length(x), y_t = x, stringsAsFactors = FALSE)
ggplot(df, aes(x = t, y = y_t)) +
geom_line(color = "blue")
# SKIP Government spending !!!
# Wrapping everything into a class
Samuelson <- R6Class(
"Samuelson",
public = list(
y_0 = NULL,
y_1 = NULL,
alpha = NULL,
beta = NULL,
gama = NULL,
n = NULL,
sigma = NULL,
g = NULL,
g_t = NULL,
duration = NA,
p1 = NA,
p2 = NA,
roots = NA,
initialize = function(y_0 = 100, y_1 = 50, alpha = 1.3, beta = 0.2, gama = 10, n = 100, sigma = 0,
g = 0, g_t = 0, duration = NA) {
self$y_0 <- y_0; self$y_1 <- y_1; self$alpha <- alpha; self$beta <- beta; self; self$gama <- gama
self$n <- n; self$sigma <- sigma; self$g <- g; self$g_t <- g_t; self$duration <- duration
self$p1 <- alpha + beta; self$p2 <- -beta
self$roots <- polyroot(c(-self$p2, -self$p1, 1))
# if (all(is.complex(self$roots))) {
# self$roots <- Re(self$roots)
# }
},
root_type = function() {
if (all(is.complex(self$roots))) {
return('Complex conjugate')
} else if (length(self$roots > 1)) {
'Double real'
} else {
'Single real'
}
},
root_less_than_one = function() {
if (all(abs(self$roots) < 1)) {
return(TRUE)
}
},
solution_type = function() {
discriminant = self$p1 ** 2 + 4 * self$p2
if (self$p2 >= 1 + self$p1 | self$p2 <= -1) {
return('Explosive oscillations')
} else if ( self$p1 + self$p2 >= 1) {
return('Explosive growth')
} else if (discriminant < 0) {
return('Damped oscillations')
} else {
return('Steady state')
}
},
transition_ = function(x, t, g) {
if (self$sigma == 0) {
return(self$p1 * x[t - 1] + self$p2 * x[t - 2] + self$gama + g)
} else {
epsilon <- rnorm(self$n, 0, 1)
return(self$p1 * x[t - 1] + self$p2 * x[t - 2] + self$gama + g + self$sigma * epsilon[t])
}
},
generate_series = function() {
# Create list and set initial conditions
y_t = c(self$y_0, self$y_1)
# Generate y_t series
for (t in 3:self$n) {
# No government spending
if (self$g == 0) {
y_t <- c(y_t, self$transition_(y_t, t, g = 0))
} else if (self$g != 0 & !is.na(self$duration)) {
# Government spending (no shock)
y_t <- c(y_t, self$transition_(y_t, t, self$g))
} else if (self$duration == 'permanent') {
# Permanent government spending shock
if (t < self$g_t) {
y_t <- c(y_t, self$transition_(y_t, t, g = 0))
} else {
y_t <- c(y_t, self$transition_(y_t, t, g = self$g))
}
} else if (self$duration == 'one-off') {
# One-off government spending shock
if (t < self$g_t) {
y_t <- c(y_t, self$transition_(y_t, t, self$g))
} else {
y_t <- c(y_t, self$transition_(y_t, t, g = 0))
}
}
}
return(y_t)
},
summary = function() {
cat(c('Summary\n', paste0(rep('-', 50), collapse = ""), "\n"))
print(paste0('Root type: ', self$root_type()))
print(paste0('Solution type: ', self$solution_type()))
print(paste0('Roots: ', self$roots))
if (self$root_less_than_one() == TRUE) {
print('Absolute value of roots is less than one')
} else {
print('Absolute value of roots is not less than one')
}
if (self$sigma > 0) {
print(paste0('Stochastic series with σ = ', self$sigma))
} else {
print('Non-stochastic series')
}
if (self$g != 0) {
print(paste0('Government spending equal to ', self$g))
}
if (!is.na(self$duration)) {
print(paste0(toupper(substring(self$duration, 1, 1)), substring(self$duration, 2),
' government spending shock at t = ', self$g_t))
}
},
plot = function() {
x <- self$generate_series()
df <- data.frame(y_t = x, t = 1:length(x))
ggplot(df, aes(x = t, y = y_t)) +
geom_line(color = "blue") +
labs(x = "Iteration", y = expression(y[t])) +
annotate("text", x = 95, y = c(50, 0.95 * 50, 0.9 * 50, 0.85 * 50, 0.8 * 50, 0.75 * 50),
label = c(paste0("alpha==", self$alpha), paste0("beta==", self$beta), paste0("gamma==", self$gama),
paste0("sigma==", self$sigma), paste0("rho[1]==", self$p1), paste0("rho[2]==", self$p2)),
size = 3, parse = TRUE)
}
)
)
S1 <- Samuelson$new(alpha = 0.8, beta = 0.5, sigma = 2, g = 10, g_t = 20, duration = 'permanent')
S1$summary()## Summary
## --------------------------------------------------
## [1] "Root type: Complex conjugate"
## [1] "Solution type: Damped oscillations"
## [1] "Roots: 0.65+0.278388218141501i" "Roots: 0.65-0.278388218141501i"
## [1] "Absolute value of roots is less than one"
## [1] "Stochastic series with <U+03C3> = 2"
## [1] "Government spending equal to 10"
## [1] "Permanent government spending shock at t = 20"S1$plot()
Rezultati u R-u su isti kao i QuantEcon Python kodovima. Ako je suditi prema uvodnim poglavljima, svi kodovi se ralativno jednostavno mogu pretoviriti u R kod. Zanimljivo je da sam za cijeli program koristio samo R6 klase i ggplot paket za vizualizacije. Bilo bi vrlo korisno i ostale modele pretvoriti u R kod, te prevesti tekst na Hrvatski. Ako bi netko pomogao u projektu, mogli bi zajdnički napraviti.
Zaključno, smatram da bi sve više kolegija na fakultetima trebalo primjenjivati QuantEcon pristup jer omogućuje raspoloživost sadržaja (internet), dostupnost znanja svima (besplatno, open source programski jezici), ponovljivost rezultata (raspoloživi kodovi), eksperimentiranje sa rezultatima modela, cjelinu znanja (teorija, podaci, programiranje, poveznice na relevantne izvore) i, ne manje važno, mnogo je zabavnije od čitanja udžbenika :)